论文首先介绍了级联老虎机模型在推荐系统和在线广告中的应用,并指出现有文献忽略了用户状态对推荐的影响以及状态变化的问题。为了解决这些问题,作者提出了级联RL框架,该框架包括状态空间和项目池,每个状态-项目对都有未知的吸引力概率、底层转移分布和确定性奖励。
级联强化学习
关键字:级联强化学习(Cascading Reinforcement Learning) 级联老虎机(Cascading Bandits) 用户状态(User States) 状态转移(State Transition) 最优项目列表(Optimal Item List) 动态规划(Dynamic Programming) 计算效率(Computation Efficiency) 样本效率(Sample Efficiency) 遗憾最小化(Regret Minimization) 最优策略识别(Best Policy Identification)

近年来,一种名为级联多臂老虎机(cascading bandits)[Kveton et al., 2015]的模型受到了广泛关注,在推荐系统、在线广告中应用广泛。在级联多臂老虎机中,智能体需要在众多选项中挑选一个选项列表推荐给用户,每个选项都有一个未知的吸引概率。智能体的目标则是不断优化推荐的选项列表,以最大化期望累积奖励(点击率)。
然而,现有的级联多臂老虎机模型忽略了用户状态(如用户历史行为)对推荐的影响,以及用户状态可能的改变。为了解决这一问题,微软亚洲研究院的研究员们提出了一种名为级联强化学习(cascading reinforcement learning)的模型。在该模型中,每个用户状态-选项的匹配对有一个未知的吸引概率、一个未知的状态转移分布和一个奖励。如图2所示,在每个时刻,智能体会先观察到当前的用户状态,然后推荐一个长度为 m 的选项列表。如果用户对某一选项感兴趣并点击,那么用户将转移到下一状态,智能体则会获得一个奖励。智能体的目标是最大化期望累积奖励,因此该模型能有效地将用户状态及其变化纳入推荐过程中。
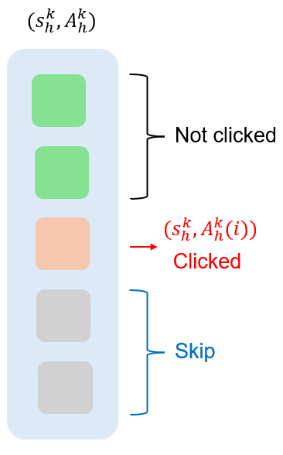
图2:级联强化学习模型
针对该模型,研究员们首先基于动态规划设计了一个快速离线求解器 BestPerm,它能够在多项式时间内计算出最优的选项列表。然后,研究员们提出了强化学习算法 CascadingVI,该算法能够达到 O ̃(H√HSNK) 的后悔度(regret)上界,这个结果只依赖于选项的个数 𝑁, 而与选项列表的个数(约 N^m)无关。因此,该算法能同时保证采样和计算的高效性。
论文核心计算主要集中在设计用于解决组合优化问题的动态规划算法BestPerm,以及两个主要算法CascadingVI和CascadingBPI中:
动态规划算法BestPerm
目的:在给定的项集合中找到最优的项列表,以最大化累积奖励。
输入:Aground(所有可能的项集合),u(吸引力概率函数),w(权重函数)。
输出:Fbest(最优值),Sbest(最优项列表)。
计算过程:
排序:根据权重w对所有项进行降序排序,得到序列a1, ..., aJ, a⊥, aJ+1, ..., aN。其中J表示权重高于虚拟项a⊥的项的数量。
初始化:设置一个二维数组F[i][k],其中i表示当前考虑的项索引,k表示要选择的项的数量。F[i][k]的初始值根据是否满足数量限制m来设定。
动态规划递推:
递推公式:
F[i][k] = max{F[i+1][k], u(ai)w(ai) + (1-u(ai))F[i+1][k-1]}
其中,第一项F[i+1][k]表示不选择当前项ai,而第二项表示选择当前项,并递归地考虑剩余的项。
终止条件:当i = 1且k = m时,F[1][m]给出了在给定约束下的最大累积奖励值。
回溯:从F[1][m]开始,通过S[i][k]数组回溯找到最优项列表Sbest。
算法CascadingVI
目的:最小化遗憾(regret),即与最优策略相比的累积性能差异。
关键计算:
探索奖励(Exploration Bonus):为每个项的吸引力概率q(s, a)和转移概率p(·|s, a)⊤V添加探索奖励,以鼓励探索。
乐观估计:计算乐观的吸引力概率¯qk(s, a)和权重¯wk(s, a),用于指导策略选择。
价值函数更新:使用BestPerm算法计算每个状态下的乐观价值函数¯V k h (s)和相应的贪婪策略πk h(s)。
算法CascadingBPI
目的:识别最佳的策略,即在给定的精度参数ε下,找到至少与最优策略几乎一样好的策略。
关键计算:
乐观估计:与CascadingVI类似,为每个项的吸引力概率和转移概率添加探索奖励,并计算乐观估计。
估计误差:构建估计误差Gk h(s),用于界定乐观价值函数与真实价值函数之间的差异。
策略输出:如果估计误差在可接受范围内(小于ε),则输出当前策略πk作为ε-最优策略。
这些计算表达式和过程是论文中提出算法的核心部分,它们共同构成了级联强化学习框架的基础,旨在解决复杂的推荐系统和在线广告中的优化问题。
论文主要贡献:展示了在强化学习领域中处理复杂推荐问题的新途径
级联强化学习框架的提出:论文提出了一种新的框架,即级联强化学习(Cascading RL),它将传统的级联老虎机模型扩展到能够考虑用户状态和状态转换的场景中。
用户状态和状态转换的考虑:与传统的级联老虎机模型不同,Cascading RL框架考虑了用户的历史行为和状态变化对推荐结果的影响,这使得模型能够更加精准地进行个性化推荐。
高效的BestPerm算法:为了解决组合动作空间带来的巨大计算挑战,论文设计了一个高效的算法BestPerm,它利用动态规划技术来快速找到最优的项目列表。
CascadingVI和CascadingBPI算法的开发:基于BestPerm算法,论文进一步开发了两个算法CascadingVI和CascadingBPI。CascadingVI旨在最小化遗憾,而CascadingBPI旨在识别最佳策略。这两个算法都具有计算和样本效率。
理论分析和保证:论文不仅提出了算法,还对这些算法进行了深入的理论分析,提供了关于遗憾和样本复杂度的界限,证明了算法的效率和有效性。
实验验证:通过在真实世界数据集上的实验,论文展示了所提出的算法相比于现有方法在计算和样本效率上的优势。
适用性:论文提出的框架和算法可以应用于多种现实世界场景,如个性化推荐系统和在线广告,这增加了研究的实用价值。
对现有研究的扩展:论文的工作不仅在理论上有所创新,而且在实际应用中也提供了新的视角,为推荐系统和在线广告等领域的研究提供了新的工具和方法。
主要技术元素:
级联强化学习框架(Cascading Reinforcement Learning, Cascading RL):
用户状态和状态转换:
组合动作空间(Combinatorial Action Space):
价值函数属性分析:
BestPerm算法:
CascadingVI算法:
CascadingBPI算法:
遗憾最小化(Regret Minimization):
最佳策略识别(Best Policy Identification):
实验验证:
理论保证:
论文链接:https://arxiv.org/abs/2401.08961



