论文主要研究了深度强化学习(DRL)中普遍存在但常被忽视的信号延迟问题。作者们首先扩展了标准的马尔可夫决策过程(MDP)框架,提出了一种新的模型——延迟观察马尔可夫决策过程(DOMDP),以纳入信号延迟。接着,他们阐述了信号延迟对DRL带来的挑战,并指出现有的DRL算法和部分可观测任务的通用方法在延迟存在时性能大幅下降。
如何应对深度强化学习中的信号延迟问题

这篇论文《ADDRESSING SIGNAL DELAY IN DEEP REINFORCEMENT LEARNING》由Wei Wang、Dongqi Han、Xufang Luo和Dongsheng Li撰写,发表在2024年的ICLR会议上。近年来,深度强化学习(DRL)及其应用迅速发展,它不仅在虚拟任务(如视频游戏和模拟机器人环境)上取得了成功,也在许多具有挑战性的现实世界任务中得到了证明,例如控制托卡马克和通过人类反馈调整大语言模型。然而,导致智能体可能无法立即观察到当前环境状态或其行动无法立即影响环境的信号延迟,在深度强化学习研究中长期存在且经常被忽视。该问题广泛存在于各种实际应用中,对基于深度强化学习解决方案的有效性产生了重大影响,因此该挑战迫切需要研究进行应对。
为了解决 DRL 中的信号延迟问题,研究员们首先通过扩展马尔可夫决策过程框架来定义延迟观测马尔可夫决策过程(DOMDP),从而将信号延迟的情况纳入考虑之中。然后,研究员们在论文中阐明了 DRL 里信号延迟存在的挑战,并展示了常规 DRL 算法和部分可观测马尔可夫决策过程(POMDP)的通用方法受到延迟的严重影响。
针对这些挑战,研究员们提出了一系列新方法,旨在提高存在延迟时 DRL 算法的性能。结合理论见解和实际算法调整,研究员们扩展了传统的 actor-critic 框架,并提出了有效的策略来克服这些挑战。实验部分,作者们在MuJoCo环境中进行了评估,比较了包括DDPG、TD3、SAC在内的多种流行的连续RL算法,以及针对POMDP的DRL算法,如基于RNN的方法和基于信念状态的方法。实验考虑了固定延迟、未固定延迟、概率状态转移和大状态空间等不同环境设置。充分的实验结果表明,在具有较大延迟的连续机器人控制任务中,采用该论文提出的方法后,DRL 算法取得了卓越的性能,其结果与无延迟情况相比,性能损失较小。
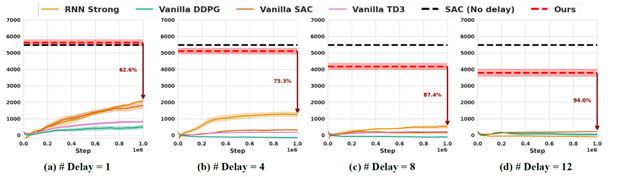
图1:该论文中的方法(红色虚线)可以在有信号延迟的情况下保持较好的效果,而其他常用的方法在有延迟的情况下表现显著下降(作为对比,黑色虚线是没有信号延迟情况下的表现)。
这项研究在解决 DRL 中一个基本挑战方面迈出了重要的一步,不仅拓宽了其在现实环境中的应用范围,也为自主系统的持续发展做出了贡献。通过开发有效应对信号延迟的方法,研究员们还讨论了未来的研究方向,包括将时间戳数据整合到模型中以优化性能,以及将研究扩展到演员-评论家框架之外,增强了 DRL 的实用性和可靠性,为其在非理想条件下的应用奠定了基础。
论文主要贡献:
通过全面的实验,研究了延迟对性能的影响,并提供了实验证据显示其显著效应。
提供了延迟问题的数学公式,包括动作和观察延迟,并得出理论见解以设计有效的解决方案。
基于提出的见解,检验了一系列缓解或克服关键挑战的方法,并对每种方法的有效性进行了实证评估。
为演员-评论家架构提出了简单通用的方法,有效解决了DRL中的信号延迟影响。
主要技术元素:
信号延迟(Signal Delay):论文探讨了在深度强化学习(DRL)中,信号延迟对学习性能的影响。
深度强化学习(Deep Reinforcement Learning, DRL):研究的主体领域,一种结合深度学习和强化学习的方法。
延迟观察马尔可夫决策过程(Delayed-Observation Markov Decision Processes, DOMDP):为处理信号延迟问题而扩展的标准MDP框架。
强化学习算法(Reinforcement Learning Algorithms):论文中讨论了多种强化学习算法,包括但不限于DDPG、TD3、SAC。
连续控制任务(Continuous Control Tasks):论文中提出的策略主要应用于连续动作空间的控制任务。
演员-评论家架构(Actor-Critic Architecture):用于强化学习的一种算法框架,论文中提出的策略基于此架构。
延迟协调训练(Delay-Reconciled Training):为评论家提出的训练方法,用于处理观察到的延迟信息。
状态增强(State Augmentation):为行动者提出的输入增强方法,帮助其在延迟情况下做出决策。
预测网络(Prediction Network):用于预测真实状态的网络,作为行动者输入的一部分。
编码网络(Encoding Network):生成用于行动者输入的隐藏特征的网络。
MuJoCo环境(MuJoCo Environments):用于实验评估的物理引擎和模拟环境。
固定延迟(Fixed Delay)和未固定延迟(Unfixed Delay):实验中考虑的两种不同的延迟设置。
概率状态转移(Probabilistic State Transition):引入随机性的实验设置,模拟现实世界的不确定性。
大状态空间(Large State Space):实验中考虑的状态空间较大的环境设置。
实证评估(Empirical Evaluation):通过实验验证所提方法的有效性。
算法性能(Algorithm Performance):衡量算法在不同设置下的性能表现。
论文链接:https://openreview.net/forum?id=Z8UfDs4J46

